EMVS: The EM Approach to Bayesian Variable Selection
Caleb Jin / 2017-12-15
Introduction
The EMVS (Rockova and George 2014) method is anchored by EM algorithm and original stochastic search variable selection (SSVS). It is a deterministic alternative to MCMC stochastic search and ideally suited for high-dimensional \(p>n\) settings. Furthermore, EMVS is able to effectively identify the sparse high-probability model and find candidate models within a fraction of the time needed by SSVS. This algorithm makes it possible to carry out dynamic posterior exploration for the identification of posterior modes.
The outline of this course project is as follows. In section 2, we build original SSVS method, including its prior and posterior distribution for each parameter. In section 3, I derive the author’s new idea EMVS method in very details that the author omits. In section 4, I perform several simulation case studies from this paper and me, then compare the results of SSVS and EMVS.
Stochastic Search Variable Selection (SSVS)
Model Settings
Consider a multiple linear regression model as follows: \[\begin{eqnarray} {\bf y}={\bf X}{\boldsymbol \beta}+ {\boldsymbol \epsilon}, \tag{1} \end{eqnarray}\] where \({\bf y}=(y_1,\ldots,y_n)^{{\top}}\) is the \(n\)-dimensional response vector, \({\bf X}=[{\bf x}_1,\ldots,{\bf x}_n]^{{\top}}\) is the \(n\times p\) design matrix, \({\boldsymbol \beta}=(\beta_1, \beta_2, \ldots, \beta_p)'\), \(\sigma^2\) is a scalar, and \({\boldsymbol \epsilon}\sim \mathcal{N}_n({\bf 0},\sigma^2{\bf I}_n)\). Both \(\sigma^2\) and \({\boldsymbol \beta}\) are considerd bo te unknown. We assume that \(p>n\). From (1), the likelihood function is given as \[\begin{eqnarray} {\bf y}|{\boldsymbol \beta}, \sigma^2 \sim \mathcal{N}({\bf X}{\boldsymbol \beta}, \sigma^2I_n). \end{eqnarray}\]The cornerstone of \(\textbf{SSVS}\) is the “spike and slab” Gaussian mixture prior on \({\boldsymbol \beta}\), \[\begin{eqnarray} \beta_j|\sigma^2,\gamma_j \stackrel{ind}{\sim} (1-\gamma_j) \mathcal{N}(0, \sigma^2\nu_0) + \gamma_j\mathcal{N}(0,\sigma^2\nu_1), \end{eqnarray}\] where \[\begin{eqnarray*} \gamma_j=\left\{ \begin{array}{lcr} 1 & \beta_j \neq 0\\ 0 & \beta_j=0, \end{array}\right. \tag{2} \end{eqnarray*}\] \(j=1,2,\ldots, p\). \(0\leq \nu_0<\nu_1\).
Hence, \({\boldsymbol \beta}|\sigma^2,{\boldsymbol \gamma}\sim \mathcal{N}_p({\bf 0},{\bf D}_{\sigma^2,{\boldsymbol \gamma}})\), where \({\bf D}_{\sigma^2,{\boldsymbol \gamma}} = \sigma^2 {\rm diag}(\nu_{z_1},\nu_{z_1},\ldots,\nu_{z_p})\).
For the prior on the \(\sigma^2\), I follow the (George and McCulloch 1997) and use inverse gamma prior but different notation, \[\begin{eqnarray} \sigma^2 \sim \mathcal{IG}(\frac{a}{2}, \frac{b}{2}), \end{eqnarray}\] where we will use \(a=1\) and \(b=1\), and \(\sigma^2\) is also independent of \({\boldsymbol \gamma}\).
I follow the (George and McCulloch 1997) and use Bernoulli prior form but different notation, \[\begin{eqnarray} \gamma_j|\theta \stackrel{iid}{\sim} Ber(\theta), \theta \in [0,1]. \end{eqnarray}\] Hence, \[\begin{eqnarray}\label{gamma} {\boldsymbol \gamma}\propto \theta^{\sum_{j=1}^{p}\gamma_j}(1-\theta)^{p-\sum_{j=1}^{p}\gamma_j} \tag{3} \end{eqnarray}\] We assume \[\begin{eqnarray} \theta \sim \mathcal{B}(c_1,c_2), \end{eqnarray}\] where we will use \(c_1=c_2=1\), which leads to the uniform distribution.
It is easy to show that the full conditionals are as follows:
- \[\beta_j|{\boldsymbol \beta}_{-j}, \sigma^2, {\boldsymbol \gamma}, \nu_0, {\bf y}\sim \mathcal{N}(\tilde{\beta}_j, \frac{\sigma^2}{\mu_j}).\] where \(\mu_j= x_j^{{\top}}x_j + \frac{1}{\nu_{\gamma_j}}\) and \(\tilde{\beta}_j = \mu_j^{-1}x_j^{{\top}}({\bf y}- {\bf X}_{-j}{\boldsymbol \beta}_{-j})\).
- \[\begin{eqnarray} \gamma_j |{\boldsymbol \gamma}_{-j}, {\boldsymbol \beta}, \sigma^2, {\bf y}\sim Ber\left(\frac{ \nu_1^{-\frac{1}{2}} \exp\left(-\frac{1}{2\sigma^2\nu_1}\beta_j^2\right)\theta} { \nu_0^{-\frac{1}{2}}\exp\left(-\frac{1}{2\sigma^2\nu_0}\beta_j^2\right)\left(1-\theta\right)+ \nu_1^{-\frac{1}{2}}\exp\left(-\frac{1}{2\sigma^2\nu_1}\beta_j^2\right)\theta}\right). \end{eqnarray}\]
- \[\sigma^2|{\boldsymbol \beta}, {\boldsymbol \gamma}, {\bf y}\sim \mathcal{IG}(a^*,b^*).\] where \(a^*=\frac{1}{2}(n+p+a)\) and \(b^* = \frac{1}{2}\left(\|{\bf y}-{\bf X}{\boldsymbol \beta}\|^2 + \sum_{j=1}^{p}\frac{\beta_j^2}{\nu_{\gamma_j}} + b\right).\)
- For \(\theta|{\boldsymbol \gamma}\), we have
\[\begin{align} \pi(\theta|{\boldsymbol \gamma})&\propto \pi({\boldsymbol \gamma}|\theta) \pi(\theta) \nonumber \\ &\propto\left[ \prod_{j=1}^p \theta^{\gamma_j}(1-\theta)^{1-\gamma_j}\right] \theta^{c_1-1}(1-\theta)^{c_2-1} \nonumber\\ &\propto \theta^{\sum_{j=1}^p \gamma_j+c_1-1}(1-\theta)^{p-\sum_{j=1}^p \gamma_j+c_2-1}, \end{align}\] where we will use \(c_1=c_2=1\), which leads to the uniform distribution. We therefore have \[\begin{eqnarray} \theta|{\boldsymbol \gamma}\sim \mathcal{B}\left(\sum_{j=1}^p \gamma_j+c_1,p-\sum_{j=1}^p \gamma_j+c_2\right). \end{eqnarray}\]
EMVS
Genared toward finding posterior modes of the parameter posterior \(\pi({\boldsymbol \beta},\sigma^2,\theta|{\bf y})\) rather than simulating from the entire model posterior \(\pi({\boldsymbol \gamma}|{\bf y})\), the EM algorithm derived here offers potentially enormous computational savings over stochastic search alternatives, especially in problems with a large number p of potential predictors.
\(\textbf{EMVS}\) consists of two steps: E-Step, conditional expectation given the observed data and current parameter estimates, and M-Step, entails the maximization of the expected complete data log posterior with respect to \(({\boldsymbol \beta},\sigma^2,\theta)\).
Define \({\boldsymbol \phi}= ({\boldsymbol \beta},\sigma^2,\theta)\). EM algorithm maximizes \(\pi({\boldsymbol \phi}|{\bf y})\) by iteratively maximizing the objective function \[\begin{eqnarray*} Q({\boldsymbol \phi}|{\boldsymbol \phi}^{(t-1)},{\bf y}) = E_{{\boldsymbol \gamma}|\cdot}[\log \pi({\boldsymbol \phi},{\boldsymbol \gamma}|{\bf y})], \end{eqnarray*}\] where \(E_{{\boldsymbol \gamma}|\cdot}\) denotes \(E_{{\boldsymbol \gamma}|{\boldsymbol \phi}^{(t-1)},{\bf y}}\).
According to the class note, it can be written as \[\begin{eqnarray} Q^{\star}({\boldsymbol \phi}|{\boldsymbol \phi}^{(t-1)},{\bf y}) = E_{{\boldsymbol \gamma}|\cdot}[\log \pi({\boldsymbol \phi}|{\boldsymbol \gamma},{\bf y})] \tag{4} \end{eqnarray}\] At the \((t-1)\)th iteration, given \({\boldsymbol \phi}^{(t-1)}\), an E-step is first applied, which computes the expectation of the right side of (4) to obtain \(Q\). This is followed by M-step, which maximizes \(Q\) over \(({\boldsymbol \beta},\sigma^2,\theta)\) to obtain \(({\boldsymbol \beta}^{(t)},\sigma^{2{(t)}},\theta^{(t)})\).
\[\begin{eqnarray*} &&Q^{\star}({\boldsymbol \beta},\sigma^2,\theta|{\boldsymbol \beta}^{(t)},\sigma^{2{(t)}},\theta^{(t)},{\bf y}) \\ &=& Q^{\star}({\boldsymbol \beta},\sigma^2,\theta|{\boldsymbol \phi}^{(t-1)},{\bf y}) \\ &=& C + Q_1({\boldsymbol \beta},\sigma^2|{\boldsymbol \phi}^{(t-1)},{\bf y}) + Q_2(\theta|{\boldsymbol \phi}^{(t-1)},{\bf y})\\ &=& C + E_{{\boldsymbol \gamma}|\cdot}[\log \pi({\boldsymbol \beta},\sigma^2|{\boldsymbol \phi}^{(t-1)},{\bf y})]+ E_{{\boldsymbol \gamma}|\cdot}[\log \pi(\theta|{\boldsymbol \phi}^{(t-1)},{\bf y})] \end{eqnarray*}\]
- \(Q_1({\boldsymbol \beta},\sigma^2|{\boldsymbol \phi}^{(t-1)},{\bf y})\) \[\begin{eqnarray*} &&\pi({\boldsymbol \beta},\sigma^2|{\boldsymbol \phi}^{(t-1)},{\bf y})\\ &\propto& \pi(y|{\boldsymbol \beta},\sigma^2)\pi({\boldsymbol \beta}|\sigma^2,{\boldsymbol \gamma})\pi(\sigma^2)\\ &\propto& (\sigma^2)^{-\frac{n}{2}}\exp\left(-\frac{1}{2\sigma^2}||y-x{\boldsymbol \beta}||^2\right) (\sigma^2)^{-\frac{p}{2}}\prod_{j=1}^{p}\nu_{\gamma_j}\exp\left(-\frac{1}{2\sigma^2\nu_{\gamma_j}}\beta_j^2\right)\\ &&\times (\sigma^2)^{-\frac{a}{2}-1}\exp\left(-\frac{b}{2\sigma^2}\right)\\ &\propto& (\sigma^2)^{-\frac{n+p+a+2}{2}}\exp\left[-\frac{1}{2\sigma^2}\left(||y-x{\boldsymbol \beta}||^2+ \sum_{j=1}^{p}\beta_j^2\frac{1}{\nu_{\gamma_j}}+b\right)\right] \end{eqnarray*}\]
\[\begin{eqnarray*} &&Q_1({\boldsymbol \beta},\sigma^2|{\boldsymbol \phi}^{(t-1)},{\bf y})\\ &=& E_{{\boldsymbol \gamma}|\cdot}[\log(\pi({\boldsymbol \beta},\sigma^2|{\boldsymbol \phi}^{(t-1)},{\bf y}))]\\ &=& -\frac{1}{2}(n+p+a+2)\log(\sigma^2)-\frac{1}{2\sigma^2}(||y-x{\boldsymbol \beta}||^2+b)-\frac{1}{2\sigma^2} \sum_{j=1}^{p}\beta_j^2E_{{\boldsymbol \gamma}|\cdot}[\frac{1}{\nu_{\gamma_j}}] \end{eqnarray*}\]
- \(Q_2(\theta|{\boldsymbol \phi}^{(t-1)},{\bf y})\) \[\begin{eqnarray*} &&\pi(\theta|{\boldsymbol \gamma},{\bf y})\\ &\propto& \pi({\boldsymbol \gamma}|\theta)p(\theta)\\ &\propto& \theta^{\sum_{j=1}^{p}\gamma_j+c_1-1}(1-\theta)^{p-\sum_{j=1}^{p}\gamma_j+c_2-1} \end{eqnarray*}\]
\[\begin{eqnarray*} &&\log(\pi(\theta|{\boldsymbol \gamma},{\bf y}))\\ &=& C+ (\sum_{j=1}^{p}\gamma_j+c_1-1)\log \theta + (p-\sum_{j=1}^{p}\gamma_j+c_2-1)\log (1-\theta)\\ &=& C+\log \frac{\theta}{1-\theta} \sum_{j=1}^{p}\gamma_j + (c_1-1)\log\theta + (p+c_2-1)\log(1-\theta) \end{eqnarray*}\]
\[\begin{eqnarray*} &&Q_2(\theta|{\boldsymbol \phi}^{(t-1)},{\bf y})\\ &=& \log \frac{\theta}{1-\theta} \sum_{j=1}^{p}E_{{\boldsymbol \gamma}|\cdot}[\gamma_j]+ (c_1-1)\log\theta + (p+c_2-1)\log(1-\theta) \\ \end{eqnarray*}\]
The E-Step
The E-step proceeds by computing the conditional expectations \(E_{{\boldsymbol \gamma}|\cdot}[\frac{1}{\nu_{\gamma_j}}]\) and \(E_{{\boldsymbol \gamma}|\cdot}[\gamma_j]\) for \(Q_1\) and \(Q_2\), respectively.
- For \(E_{{\boldsymbol \gamma}|\cdot}[\gamma_j]\),
\[\begin{eqnarray*} &&\pi(\gamma_j|\theta,\beta_j,\sigma^2,{\bf y})\\ &\propto&\pi(\beta_j|\gamma_j,\sigma^2)p(\gamma_j|\theta)\\ &\propto&\nu_{\gamma_j}^{-\frac{1}{2}}\exp\left(-\frac{1}{2\sigma^2\nu_{\gamma_j}}\beta_j^2\right) \theta^{\gamma_j}(1-\theta)^{1-\gamma_j} \end{eqnarray*}\]
Hence, \(\pi(\gamma_j=1|\theta,\beta_j,\sigma^2,{\bf y})=C \nu_{1}^{-\frac{1}{2}}\exp\left(-\frac{1}{2\sigma^2\nu_{1}}\beta_j^2\right)\theta\equiv a_i\),
\(\pi(\gamma_j=0|\theta,\beta_j,\sigma^2,{\bf y})=C \nu_{0}^{-\frac{1}{2}}\exp\left(-\frac{1}{2\sigma^2\nu_{0}}\beta_j^2\right)(1-\theta)\equiv b_i\).
Hence,
\[\begin{eqnarray*} &&E_{{\boldsymbol \gamma}|\cdot}[\gamma_j]=\pi(\gamma_j=1|\theta,\beta_j,\sigma^2,{\bf y})\\ &=&\frac{\pi(\gamma_j=1,\Omega)}{\sum_{\gamma_j}\pi(\gamma_j,\Omega)}\\ &=&\frac{C \nu_{1}^{-\frac{1}{2}}\exp\left(-\frac{1}{2\sigma^2\nu_{1}}\beta_j^2\right)\theta} {C \nu_{1}^{-\frac{1}{2}}\exp\left(-\frac{1}{2\sigma^2\nu_{1}}\beta_j^2\right)\theta +C \nu_{0}^{-\frac{1}{2}}\exp\left(-\frac{1}{2\sigma^2\nu_{0}}\beta_j^2\right)(1-\theta)}\\ &=&\frac{ \nu_{1}^{-\frac{1}{2}}\exp\left(-\frac{1}{2\sigma^2\nu_{1}}\beta_j^2\right)\theta} {\nu_{1}^{-\frac{1}{2}}\exp\left(-\frac{1}{2\sigma^2\nu_{1}}\beta_j^2\right)\theta + \nu_{0}^{-\frac{1}{2}}\exp\left(-\frac{1}{2\sigma^2\nu_{0}}\beta_j^2\right)(1-\theta)}\\ &=&p_i^* \end{eqnarray*}\]
Hence,
\[\begin{eqnarray} &&Q_2(\theta|{\boldsymbol \phi}^{(t-1)},{\bf y})\nonumber\\ &=& \log \frac{\theta}{1-\theta} \sum_{j=1}^{p}p_i^*+ (c_1-1)\log\theta + (p+c_2-1)\log(1-\theta) \tag{5} \end{eqnarray}\]
- For \(E_{{\boldsymbol \gamma}|\cdot}[\frac{1}{\nu_{\gamma_j}}]\), \[\begin{eqnarray*} &&E_{{\boldsymbol \gamma}|\cdot}[\frac{1}{\nu_{\gamma_j}}]\\ &=&p(\gamma_j=1|\cdot)\frac{1}{\nu_{\gamma_j=1}} + p(\gamma_j=0|\cdot)\frac{1}{\nu_{\gamma_j=0}}\\ &=& \frac{p_i^*}{\nu_{1}}+\frac{1-p_i^*}{\nu_{0}} \equiv d^*_i \end{eqnarray*}\] Hence, \[\begin{eqnarray} &&Q_1({\boldsymbol \beta},\sigma^2|{\boldsymbol \phi}^{(t-1)},{\bf y})\nonumber\\ &=& -\frac{1}{2}(n+p+a+2)\log(\sigma^2)-\frac{1}{2\sigma^2}(||{\bf y}-x{\boldsymbol \beta}||^2+b)-\frac{1}{2\sigma^2} \sum_{j=1}^{p}\beta_j^2d^*_i \nonumber\\ &=& -\frac{1}{2}(n+p+a+2)\log(\sigma^2)-\frac{1}{2\sigma^2}(||{\bf y}-x{\boldsymbol \beta}||^2+b)-\nonumber\\ &&\frac{1}{2\sigma^2} ||{\bf D}^{*1/2}{\boldsymbol \beta}||^2, \tag{6} \end{eqnarray}\] where \({\bf D}^*={\rm diag}\{d_i^*\}_{i=1}^{p^*}\)
The M-Step
Maximize \(Q_1\)
\({\boldsymbol \beta}\) values that maximizes \(Q1\) in Eq.(6) is equivalent to \[ {\boldsymbol \beta}^{(t)}=\arg\min_{{\boldsymbol \beta}\to\mathcal{R}^p}||{\bf y}-x{\boldsymbol \beta}||^2+||{\bf D}^{*1/2}{\boldsymbol \beta}||^2. \] This is quickly obtained by the well-known solution to the ridge regression problem: \[ {\boldsymbol \beta}^{(t)} = ({\bf X}^{{\top}}{\bf X}+{\bf D}^*)^{-1}{\bf X}^{{\top}}{\bf y} \]
Given \({\boldsymbol \beta}^{(t)}\), solve the solution of \(\frac{\partial Q_1}{\partial \sigma^2}\), we can easily obtain \[ \sigma^{2(t)} = \frac{||{\bf y}-{\bf X}{\boldsymbol \beta}^{(t)}||^2+ ||{\bf D}^{*1/2}{\boldsymbol \beta}^{(t)}||^2 + b}{n+p+a+2}. \]
- Maximize \(Q_2\)
\[\begin{eqnarray*} &&\frac{\partial Q_2}{\partial \theta}\\ &=& \frac{1-\theta}{\theta}\frac{1-\theta+\theta}{(1-\theta)^2}\sum_{j=1}^{p}p_j^*+\frac{a-1}{\theta}-\frac{p+b-1}{1-\theta}\\ &=&\frac{\sum_{j=1}^{p}p_j^*}{\theta(1-\theta)}+\frac{a-1}{\theta}-\frac{p+b-1}{1-\theta}\\ &=&\frac{\sum_{j=1}^{p}p_j^*-(a+b+p-2)\theta+a-1}{\theta(1-\theta)}\\ &\equiv& 0 \end{eqnarray*}\] Hence, we have \(\theta^{(t)}=\frac{\sum_{j=1}^{p}p_j^*+a-1}{a+b+p-2}\).
Simulation Case Study
According to this paper, the author simulate a dataset consisting of \(n=100\) observations and \(p=1000\) predictors. Predictor values for each observation were sampled from \(\mathcal{N}_p({\bf 0},{\boldsymbol \Sigma})\) where \({\boldsymbol \Sigma}= (\rho_{ij})_{i,j=1}^p\) with \(\rho_{ij}=0.6^{|i-j|}\). Response values were then generated according to the linear model \({\bf y}={\bf X}{\boldsymbol \beta}+{\boldsymbol \epsilon}\), where \({\boldsymbol \beta}=(3,2,1,0,0,\ldots,0)^{{\top}}\) and \({\boldsymbol \epsilon}\sim \mathcal{N}_n({\bf 0},\sigma^2{\bf I}_n)\) with \(\sigma^2 = 3\).
The R code is shown below
library(mvtnorm)
library(ggplot2)
library(reshape2)
n <- 100
p <- 1000
beta <- c(3,2,1,rep(0,p-3))
Sigma <- matrix(NA,p,p)
for (i in 1:p) {
for (j in 1:p) {
Sigma[i,j] = 0.6^(abs(i-j))
}
}
set.seed(2144)
x <- matrix(rmvnorm(n,mean = rep(0,p), sigma = Sigma),nrow = n)
y <- x%*%beta + rnorm(n,0,sqrt(3))
## prior and initial values
MC = 20
nu0 = 0.5
nu1 <- 1000
hat.theta = rep(1,MC)
hat.theta[1] = 0.5
hat.gamma <- rep(1, p)
hat.beta = matrix(NA,nrow = MC, ncol = p)
hat.beta[1,] = rep(1,p)
hat.sig2 <- rep(NA,MC)
hat.sig2[1] <- 1#mean((y - x %*% hat.beta[1,])^2)
for (i in 2:MC) {
a <- dnorm(hat.beta[i-1,],0,sd = sqrt(hat.sig2[i-1]*nu1))*(hat.theta[i-1])
b <- dnorm(hat.beta[i-1,],0,sd = sqrt(hat.sig2[i-1]*nu0))*(1-hat.theta[i-1])
p.star = a/(a+b)
D.star <- diag((1-p.star)/nu0+p.star/nu1)
D.star.5 <- diag(sqrt((1-p.star)/nu0+p.star/nu1))
hat.beta[i,] <- solve(t(x)%*%x+D.star)%*%t(x)%*%y
hat.sig2[i] <- (t(y-x%*%hat.beta[i,])%*%(y-x%*%hat.beta[i,]) +
t(D.star.5%*%hat.beta[i,])%*%(D.star.5%*%hat.beta[i,]) + 1)/(n+p+1+1)
hat.theta[i] <- sum(p.star)/(p)
# hat.theta[i] = 0.5
##################################################
## uncomment if you want to see the convergence ##
# plot(beta,hat.beta[i,], ylim = c(-0.5,3))
# abline(h = 0, col = 4)
# abline(a=0,b=1,lty=2)
# print(i)
}
data1 <- data.frame(beta=beta,hat.beta=hat.beta[MC,])
fig1 <- ggplot(data1,aes(beta,hat.beta))+
geom_point(color = 'red',size = 2,alpha = 0.7)+
ylab(expression(hat(beta)))+
xlab(expression(beta))+
ylim(c(-0.3,3)) +
ggtitle(label = 'MAP Estimate versus True Coefficients')+
geom_abline(intercept = 0, slope = 1,lty = 2)+
theme(axis.title.x = element_text(size=12),
axis.title.y = element_text(size=12),
axis.text.x = element_text(size=12),
axis.text.y = element_text(size=12))
# print hat.theta and hat.sigma
print(round(c(hat.theta[MC],sqrt(hat.sig2[MC])),4))## [1] 0.0031 0.0404Beginning with an illustration of the \(\textbf{EM}\) algorithm from the section 3, we apply it to the simulated data using the spike-and-slab prior (2) with a single value \(\nu_0=0.5, \nu_1 = 1000\), and the \(\theta\sim U(0,1)\). The starting values for the \(\textbf{EM}\) algorithm were set to \(\sigma^{2(0)}=1\) and \({\boldsymbol \beta}^{(0)}=\bf{1}_p\). After only four iterations, the algorithm obtained the modal coefficient estimates \(\hat{{\boldsymbol \beta}}\) depicted in Figure 1, displaying the estimated \({\boldsymbol \beta}\) and true \({\boldsymbol \beta}\). In my case, the associated modal estimates of \(\hat{\theta}\) and \(\hat{\sigma^2}\) were 0.003 and 0.040, respectively; which are very similar to results of the paper.
For comparison, I applied the same formulation except with the Bernoulli prior (3) under fixed \(\theta=0.5\) Figure 2. Note the inferiority of the estimates near zero due to the lack of adaptivity of the Bernoulli prior in determining the degree of underlying sparsity.

Figure 1: Modal estimates of the regression coefficients
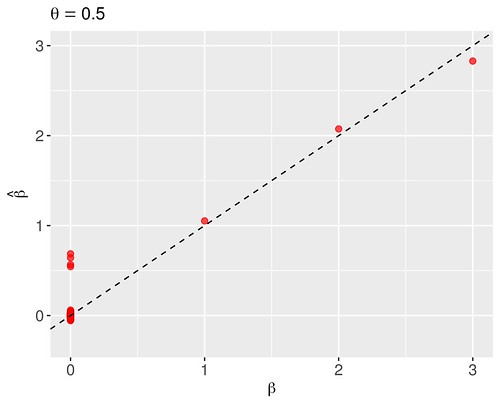
Figure 2: Modal estimates of the regression coefficients
The effect of different \(\nu_0\) and \({\boldsymbol \beta}^{(0)}\) values on variable selection
Rather than fixing \(\nu_0\) as 0.5, I vary it from 0 to 0.5 to see its effect on the variable selection. I imitate the author’s method to consider the grid of \(\nu_0\) values \(V=\{0.01+k\times 0.01:k=0,\ldots,50\}\) again with \(\nu_1=1000\) fixed and \({\boldsymbol \beta}^{(0)}=\bf{1}_p\). Figure 3 shows the modal estimates of regression coefficients obtained for each \(\nu_0\in V\). We can discover that only when \(\nu_0 >0.15\), we can get a good estimation for the \({\boldsymbol \beta}\).I also consider the effect different initial values of \({\boldsymbol \beta}\) on the variable selection. Fix \(\nu_0=0.5\) and \(\nu_1=1000\), I set the grid of \({\boldsymbol \beta}^{(0)}=\bf{c}_p\) where \(\bf{c}\) is a p-dimension vector with each value \(c_i = \{-5+0.2\times k:k=0,\ldots,50\}, i=1,2,\ldots,p\). Figure 4 depicts modal estimates of regression coefficients with different initial values of \({\boldsymbol \beta}^{(0)}\). We discover only when \(|{\boldsymbol \beta}^{(0)}|<2\), we can get good estimation for the \({\boldsymbol \beta}\).
I also consider the effect different initial values of \({\boldsymbol \beta}\) on the variable selection. Fix \(\nu_0=0.5\) and \(\nu_1=1000\), I set the grid of \({\boldsymbol \beta}^{(0)}=\bf{c}_p\) where \(\bf{c}\) is a p-dimension vector with each value \(c_i = \{-5+0.2\times k:k=0,\ldots,50\}, i=1,2,\ldots,p\). Figure 4 depicts modal estimates of regression coefficients with different initial values of \({\boldsymbol \beta}^{(0)}\). We discover only when \(|{\boldsymbol \beta}^{(0)}|<2\), we can get good estimation for the \({\boldsymbol \beta}\).
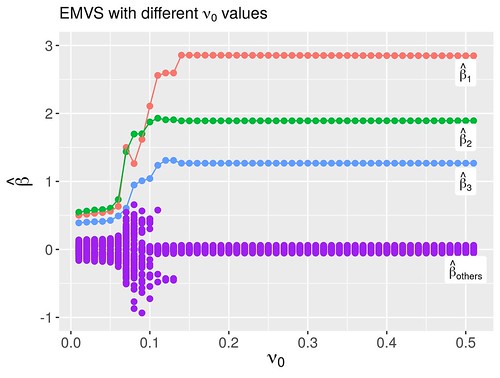
Figure 3: Modal estimates of the regression coefficients

Figure 4: Modal estimates of the regression coefficients
Reference
George, Edward I., and Robert E. McCulloch. 1997. “APPROACHES for Bayesian Variable Selection.” Statistica Sinica 7 (2): 339–73. http://www.jstor.org/stable/24306083.
Rockova, Veronika, and Edward George. 2014. “EMVS: The Em Approach to Bayesian Variable Selection.” Journal of the American Statistical Association 109 (June). https://doi.org/10.1080/01621459.2013.869223.